Developing Spark Java Api Endpoints using Annotations
Developing Spark Java Api Endpoints using Annotations
“Spark Framework is a simple and expressive Java/Kotlin web framework DSL built for rapid development.”
A quick look on sparkjava.com and you will see how easy it is to use, it literally takes a few minutes to get spark project up and running.
A sample example screenshot straight from the website :
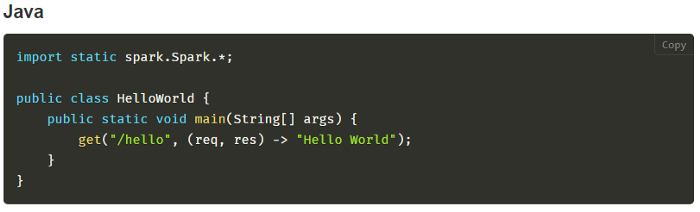
It looks so easy and tempting which I booted up my laptop and in a few clicks on IntelliJ Community Edition my “Hello World” (the above example) was up and running.
Next I went through some tutorials and that is when I started getting : “This will get ugly as the API expands feeling”.
Meaning: As you add more API end points to the above file and it will start to look cluttered, even if you move your logic to different class (which you should), still you will end up with a file full of endpoints.
Now I can totally see you thinking :
“Developers like him do not understand the concept of micro services, Micro services should be well… micro, with a few endpoints and each business functionality having its own automated build-deployment pipeline !.”
You are correct, I get that, please calm down !.
Even with say five endpoints, I don’t get the warm and fuzzes when I look at the “Endpoint File”, it feels unnecessary (at least for my usage).
I may be wrong but for me having the functionality to add @Get or @Post to the endpoint makes it easy to write/read.
So in this article I will explain how to add annotations to the above example.
So I created annotations first :
SparkApi annotation is a marker annotation that is to mark the class using it as an API class.
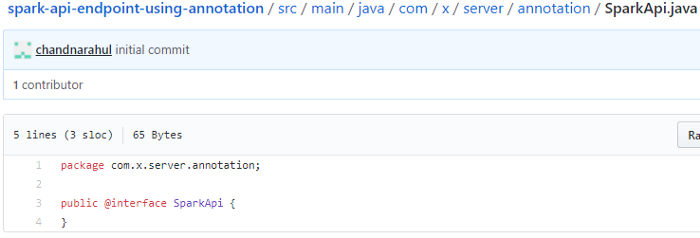
Source
- Get Annotation is for HTTP Get calls.
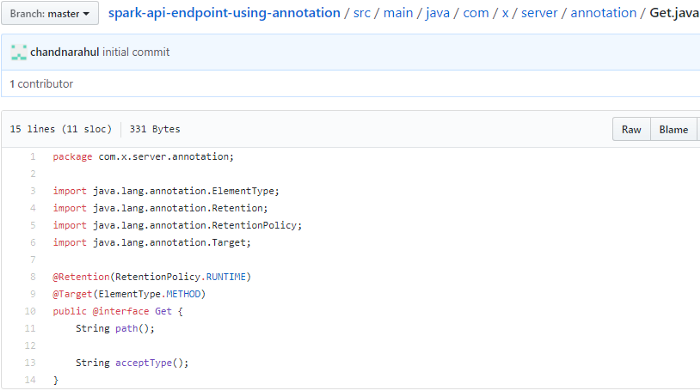
- Post annotation is for HTTP Post calls.

Here RetentionPolicy.RUNTIME is used because I need this annotation to be present at runtime so that I can use it to search for classes and for both Get and Post I have added methods Path and Accept Type, this is because I am going to call the below Spark methods.


Now the above annotations can be used in HelloWorld example.

In above code at :
Line 9 : SparkApi annotation is used to mark this class as spark API class.
Line 19: Post annotation is used to mark method as responsible for handling HTTP post requests to the specified URL path and accept type.
Line 24: Get annotation is used to mark method as responsible for handling HTTP post requests to the specified URL path and accept type. This also shows how to handle query parameters.
Line 33: Get annotation is used to mark method as responsible for handling HTTP post requests to the specified URL with path parameter and accept type.
- Now lets start the server and register all endpoints

- Now an external Reflections dependency is used, that will search for all classes with @SparkApi annotation.
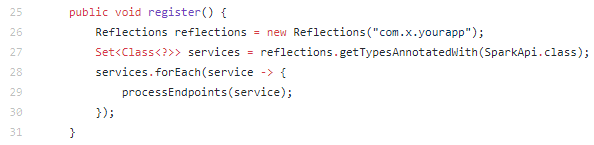
- Once all the classes have been found, next it will look for all methods with @Get and @Post annotations.

- Then it will call spark Get/Post method to add the endpoint.
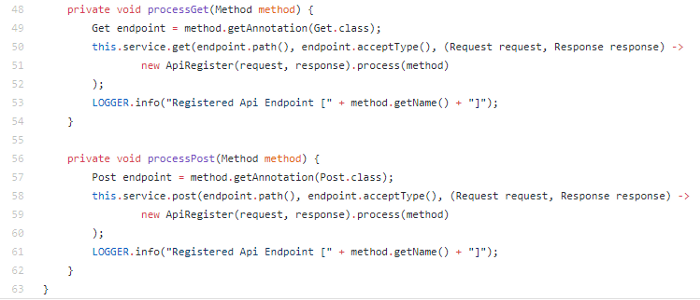
- Now last bit is to tell Spark what class and method to call when the path in “endpoint.path()” is called.
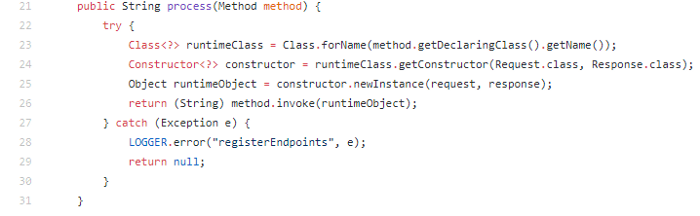
In above code at:
Line 23 : method object gets the class it is declared in.
Line 24 : HellowWorld class is overriding constructor with spark request, response, so here I am creating a new instance of the class using that constructor.
Line 25 : the method that we found using @Get/@Post annotation executes.
Every time endpoint loads the above code will be executed.
Which is why I do not like this piece of code because reflection is a bit slower compared to directly creating an instance of class.
So some performance testing will make me feel more comfortable I guess.
So here you go, that is it !, now when server starts it will call reflections dependency to:
- Search for all classes with @SparkApi annotation.
- Search for all methods in that class with @Get/@Post annotations.
- Add that method to Spark get/post method
- A new instance of that method will be called each time endpoint is hit.
Above Source Code:
References